

Identificare gli step successivi in Power Automate
Recentemente mi è capitata una problematica di questo tipo in Power Automate, dato un set di dati che rappresentano dei task da completare
In pratica, il desiderata era che, ogni volta che un task veniva completato, (stato Approved), dovevano essere identificati i processi non ancora completati, (stato Created), dipendenti da quelli completati (proprietà predecessor).
Quindi in base ai dati di esempio precedenti il risultato doveva essere questo:
Flow
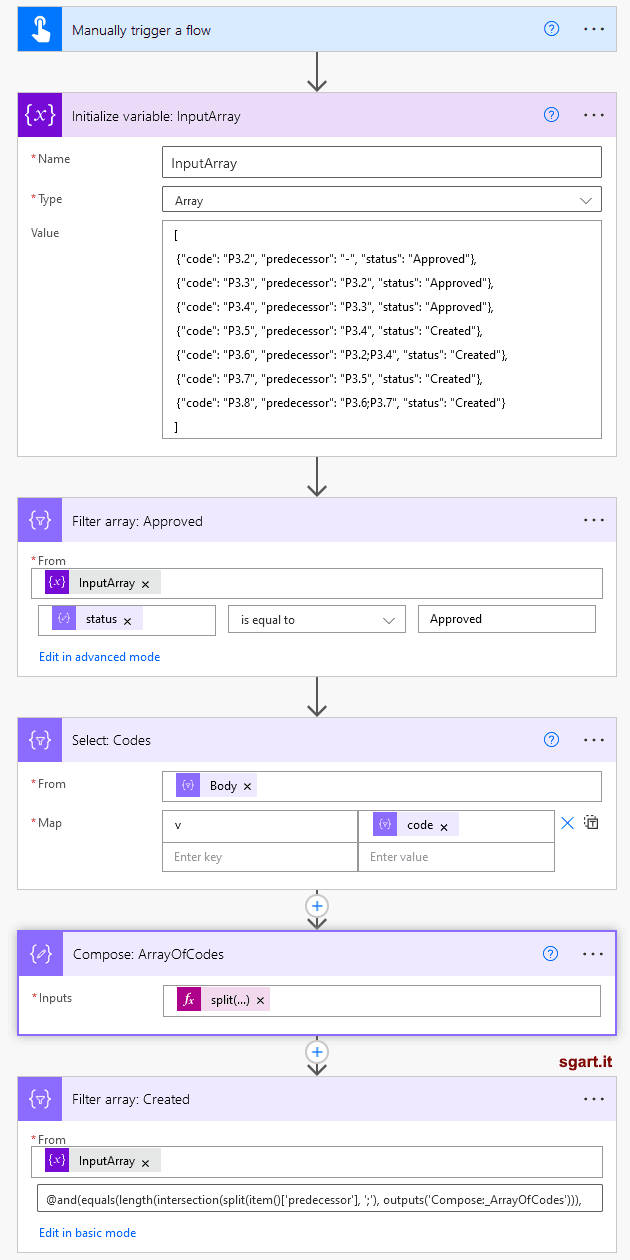
I dati di ingresso, normalmente presi da una sorgente dati, li ho rappresentati con la variabile InputArray
Il passo successivo è identificare i task già approvati
Infine possiamo selezionare solo gli elementi successi, acora da completare (stato Created), che dipendono da quelli completati
Il risultato è questo
L'unico Apply to each sarà quello finale per ciclare sull'array risultate e aggiornare la sorgente dati.
Ad esempio questa espressione con 3 array di numeri
JSON: sorgente di esempio
[
{"code": "P3.2", "predecessor": "-", "status": "Approved"},
{"code": "P3.3", "predecessor": "P3.2", "status": "Approved"},
{"code": "P3.4", "predecessor": "P3.3", "status": "Approved"},
{"code": "P3.5", "predecessor": "P3.4", "status": "Created"},
{"code": "P3.6", "predecessor": "P3.2;P3.4", "status": "Created"},
{"code": "P3.7", "predecessor": "P3.5", "status": "Created"},
{"code": "P3.8", "predecessor": "P3.6;P3.7", "status": "Created"}
]
In pratica, il desiderata era che, ogni volta che un task veniva completato, (stato Approved), dovevano essere identificati i processi non ancora completati, (stato Created), dipendenti da quelli completati (proprietà predecessor).
Quindi in base ai dati di esempio precedenti il risultato doveva essere questo:
JSON: Risultato
[
{"code": "P3.5", "predecessor": "P3.4", "status": "Created"},
{"code": "P3.6", "predecessor": "P3.2;P3.4", "status": "Created"},
]
Realizzazione
La realizzazione volevo che fosse il più possibile efficiente, quindi ho escluso a priori l'uso dei cicli come Apply to each ed ho usato solo le funzioni di Data operation.I dati di ingresso, normalmente presi da una sorgente dati, li ho rappresentati con la variabile InputArray
Power Automate: Initialize variable: InputArray (Array)
[
{"code": "P3.2", "predecessor": "-", "status": "Approved"},
{"code": "P3.3", "predecessor": "P3.2", "status": "Approved"},
{"code": "P3.4", "predecessor": "P3.3", "status": "Approved"},
{"code": "P3.5", "predecessor": "P3.4", "status": "Created"},
{"code": "P3.6", "predecessor": "P3.2;P3.4", "status": "Created"},
{"code": "P3.7", "predecessor": "P3.5", "status": "Created"},
{"code": "P3.8", "predecessor": "P3.6;P3.7", "status": "Created"}
]
Il passo successivo è identificare i task già approvati
Power Automate: Filter array: Approved
From: variables('InputArray')
@equals(item()['status'], 'Approved')
Power Automate: Select: Codes
From: body('Filter_array:_Approved')
Map: v = item()['code']
Power Automate: Compose: ArrayOfCodes
Inputs: split(slice(join(body('Select:_Codes'), ''), 6, -2), '"}{"v":"')
JSON
[
"P3.2",
"P3.3",
"P3.4"
]
Infine possiamo selezionare solo gli elementi successi, acora da completare (stato Created), che dipendono da quelli completati
Power Automate: Filter array: Created
From: variables('InputArray')
Inputs: @and(equals(length(intersection(split(item()['predecessor'], ';'), outputs('Compose:_ArrayOfCodes'))), length(split(item()['predecessor'], ';'))),equals(item()['status'],'Created'))
Il tutto grazie alla funzione intersection(array1, array2) che ritorna solo gli elementi che coincidono, nei due array passati.
Poi confrontando la lunghezza dell'array risultante con l'array di partenza: length(split(item()['predecessor'], ';')).
Poi confrontando la lunghezza dell'array risultante con l'array di partenza: length(split(item()['predecessor'], ';')).
Il risultato è questo
JSON: Risultato elementi dipendenti dai precedenti
[
{
"code": "P3.5",
"predecessor": "P3.4",
"status": "Created"
},
{
"code": "P3.6",
"predecessor": "P3.2;P3.4",
"status": "Created"
}
]
L'unico Apply to each sarà quello finale per ciclare sull'array risultate e aggiornare la sorgente dati.
intersection
La funzione intersection(array1, array2, arrayN) restituice un array con i soli elementi presenti in tutti gli array passati.Ad esempio questa espressione con 3 array di numeri
Power Automate
intersection(split('1|2|3|4','|'),split('4|1','|'),split('7|4|8|4|1','|'))
JSON
[
"1",
"4"
]